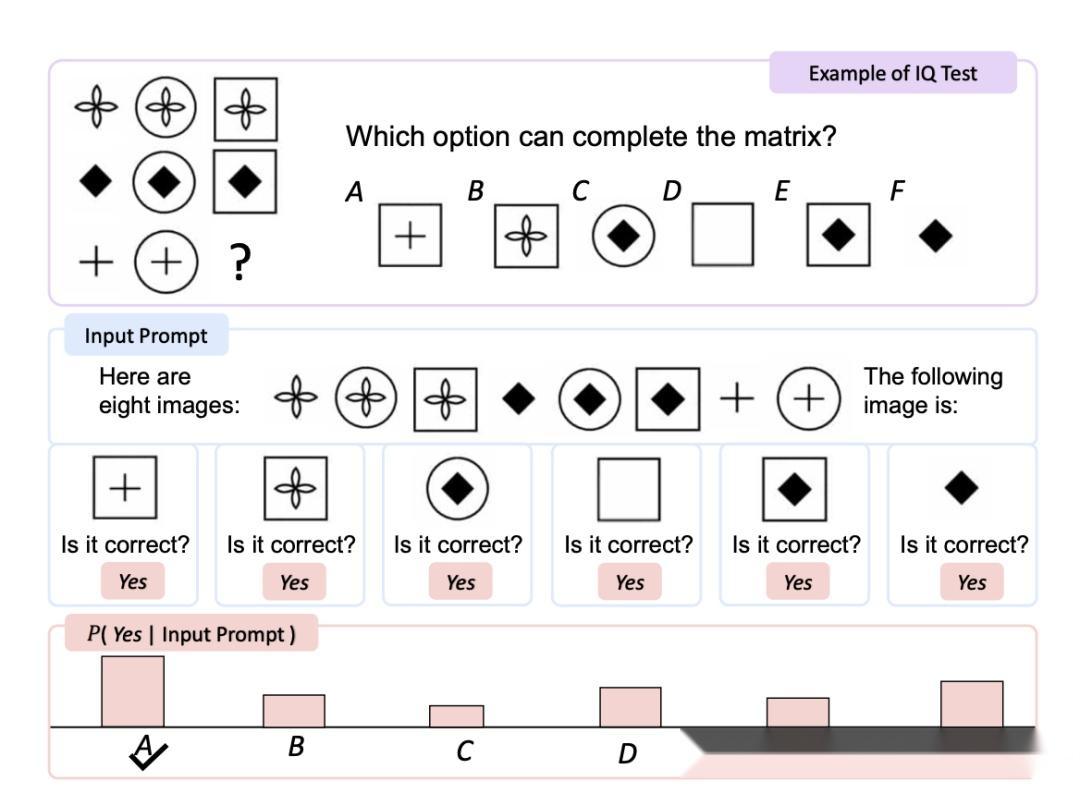
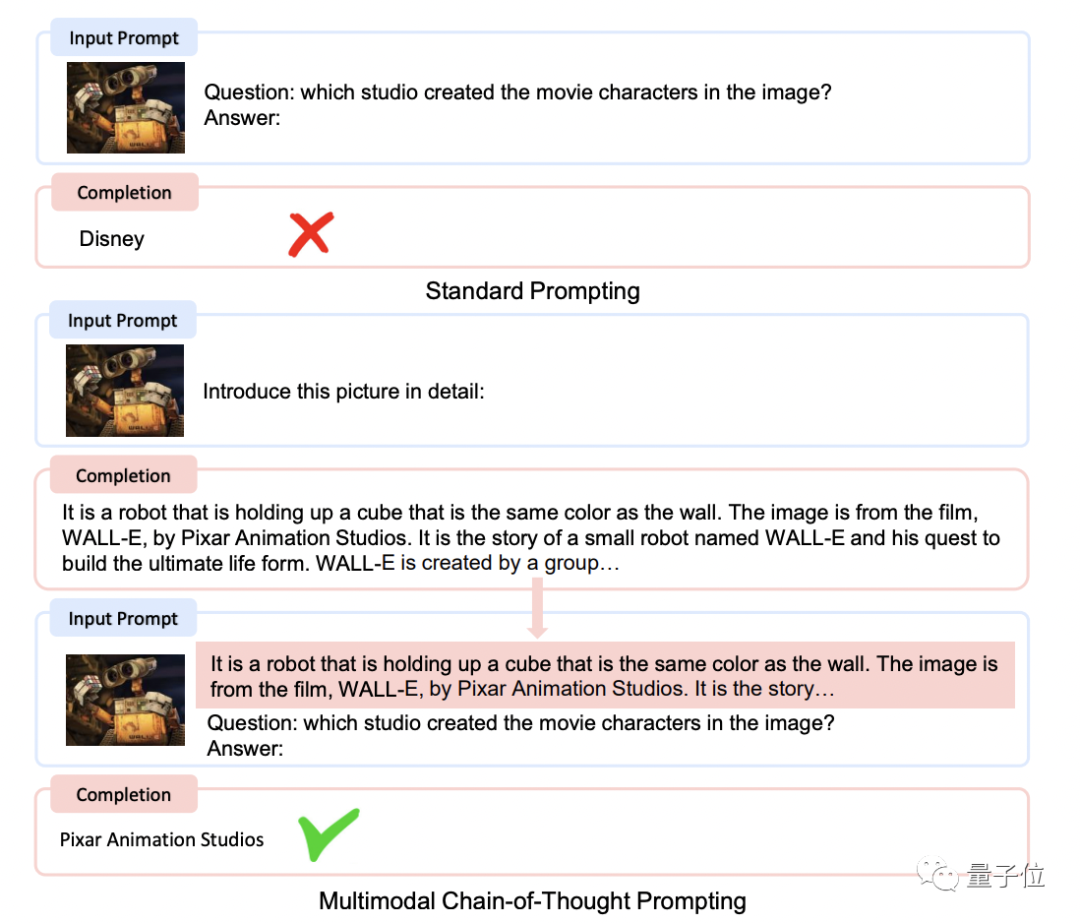
Kosmos-1的骨干网络,是一个基于Transformer的因果语言模型。Transformer解码器作为通用接口,用于多模态输入。
用于训练的数据来自多模态语料库,包括单模态数据(如文本)、跨模态配对数据(图像-文本对)和交错的多模态数据。
值得一提的是,虽说“Language is not all you need”,但为了让Kosmos-1更能读懂人类的指示,在训练时,研究人员还是专门对其进行了仅使用语言数据的指令调整。
具体而言,就是用(指令,输入,输出)格式的指令数据继续训练模型。
实验结果



 发表于 2023-3-4 05:58:30
发表于 2023-3-4 05:58:30