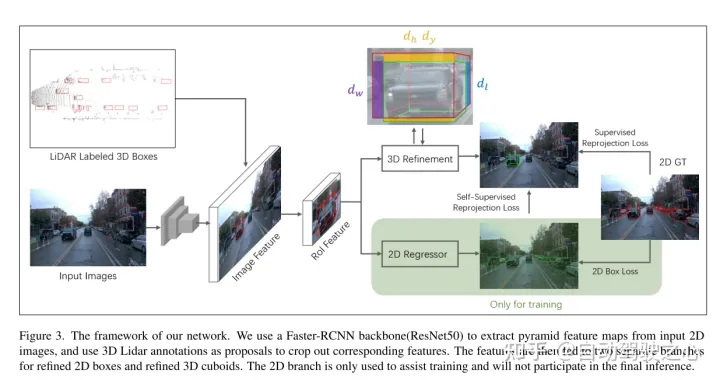
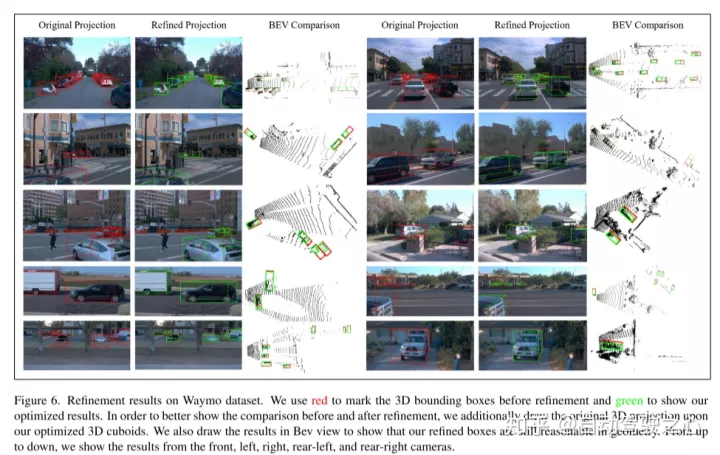
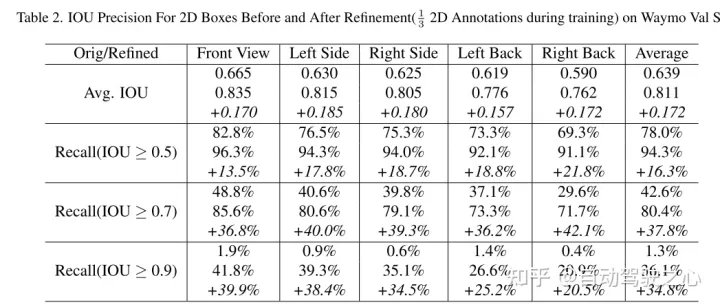
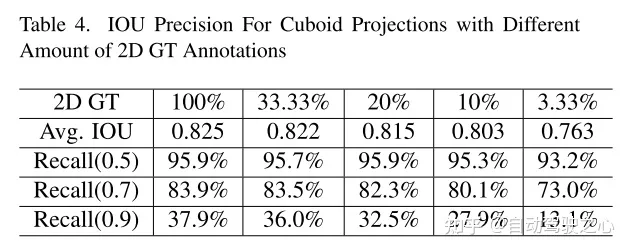
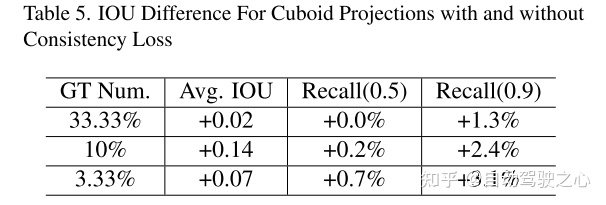
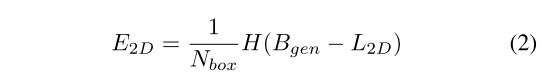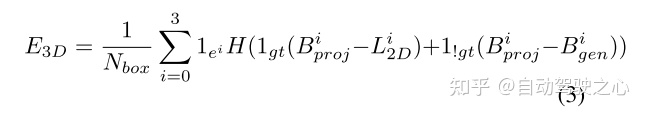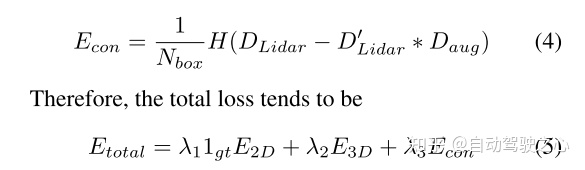4
8
16
新手上路
使用道具 举报
0
6
11
本版积分规则 发表回复 回帖后跳转到最后一页
Archiver|手机版|小黑屋|VV游戏
GMT+8, 2026-3-26 13:41 , Processed in 0.095703 second(s), 20 queries .
Powered by Discuz! X3.4
Copyright © 2001-2021, Tencent Cloud.



 发表于 2022-12-9 20:45:03
发表于 2022-12-9 20:45:03