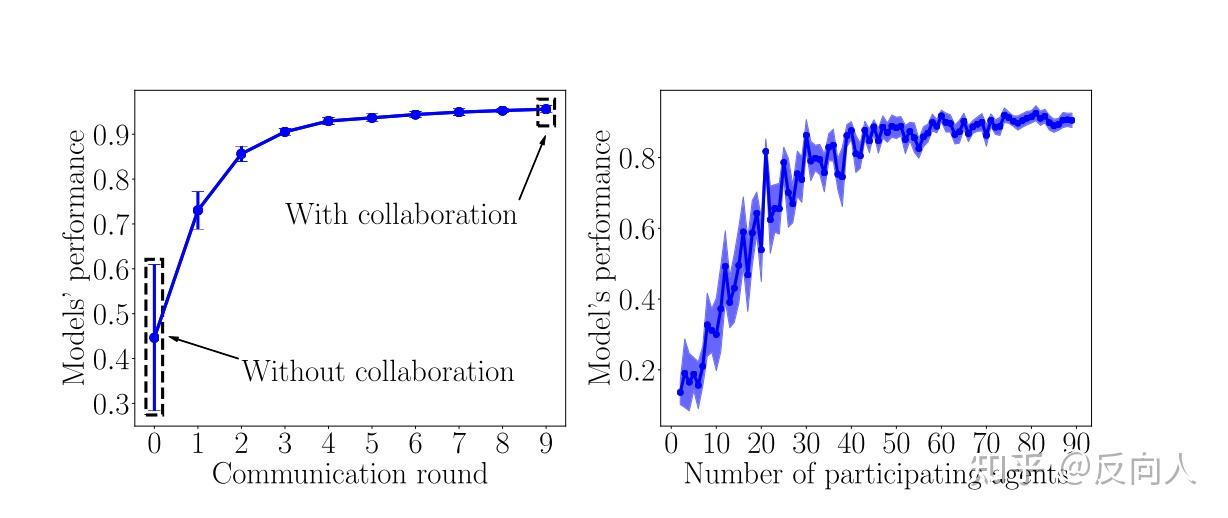
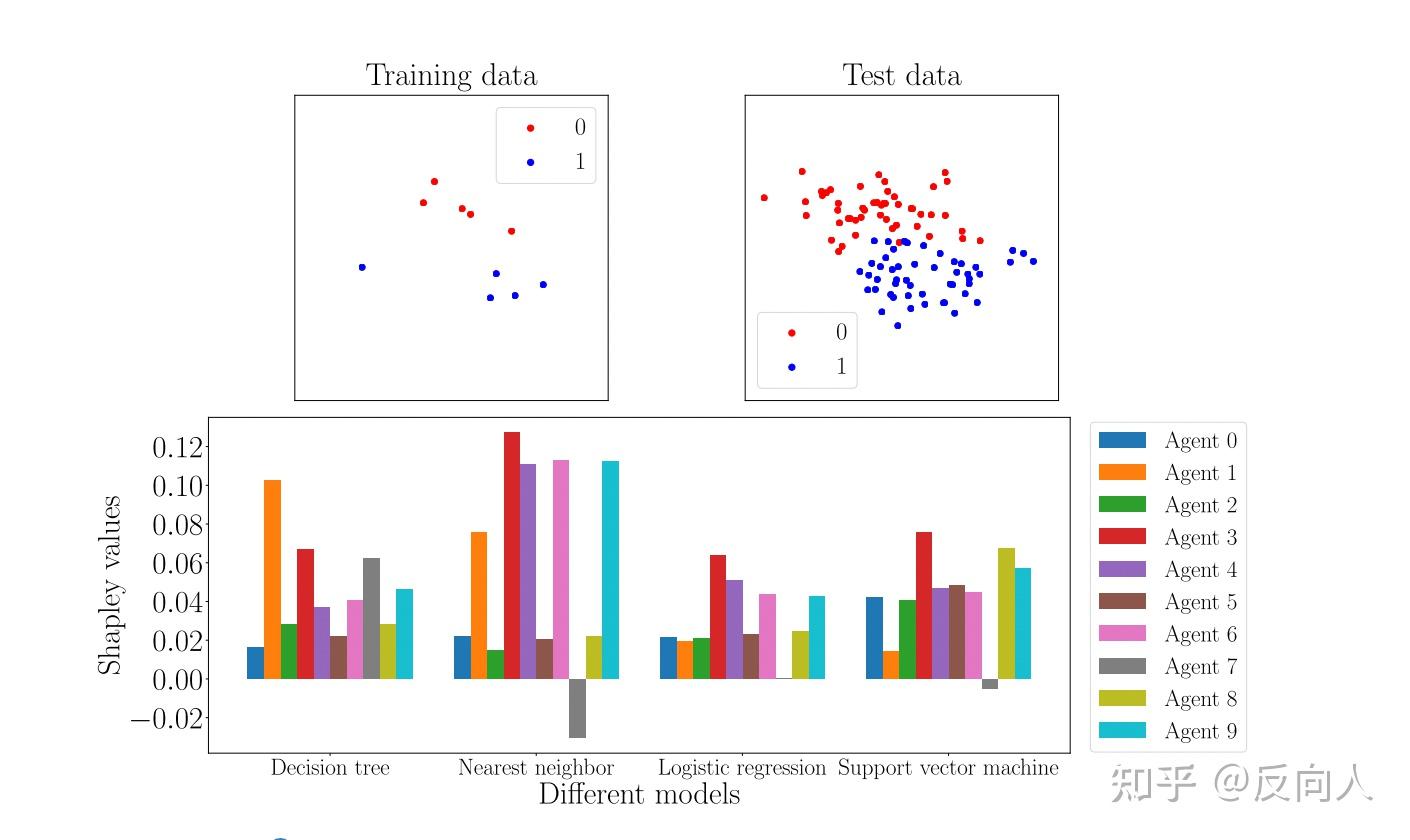
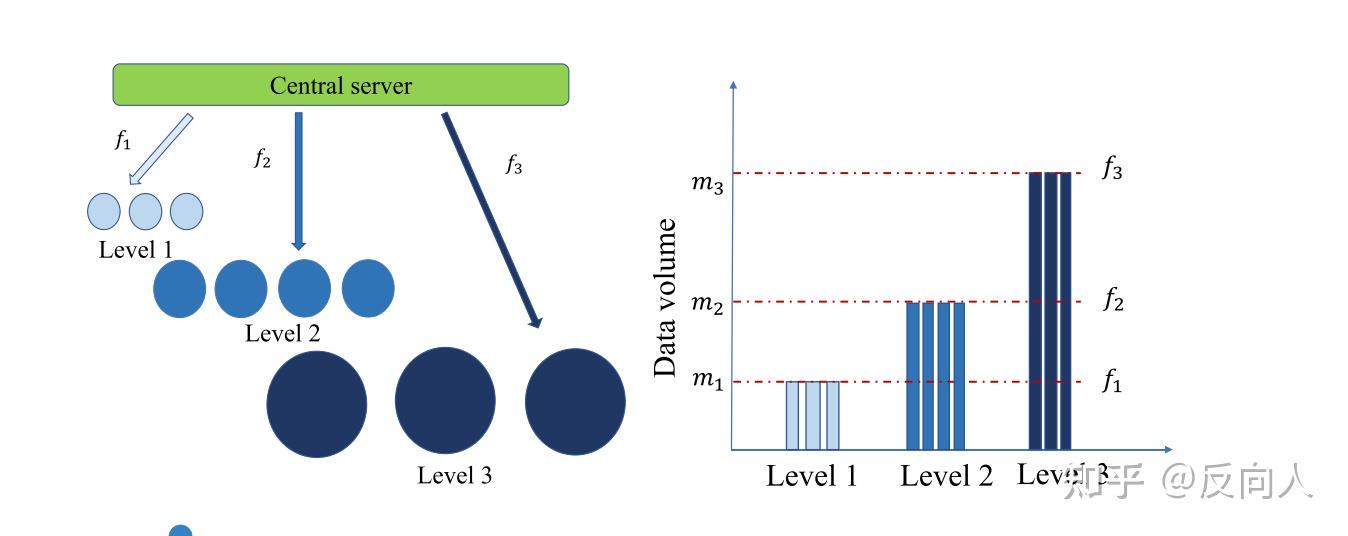
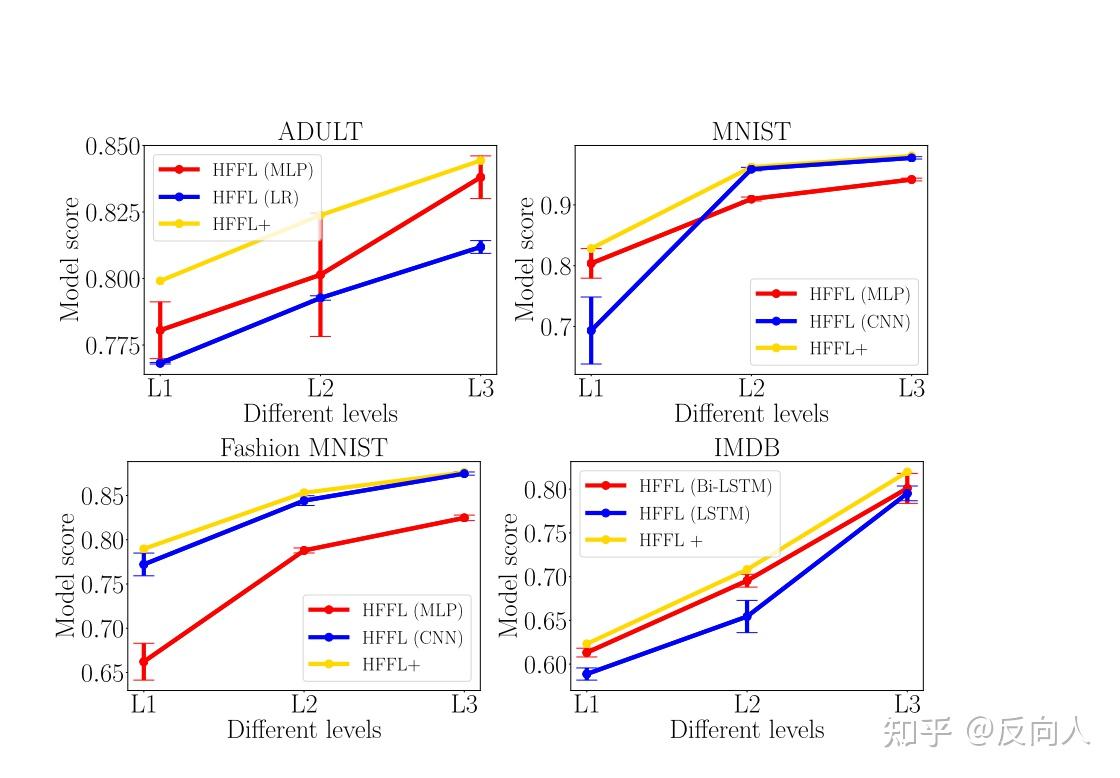
3
7
13
新手上路
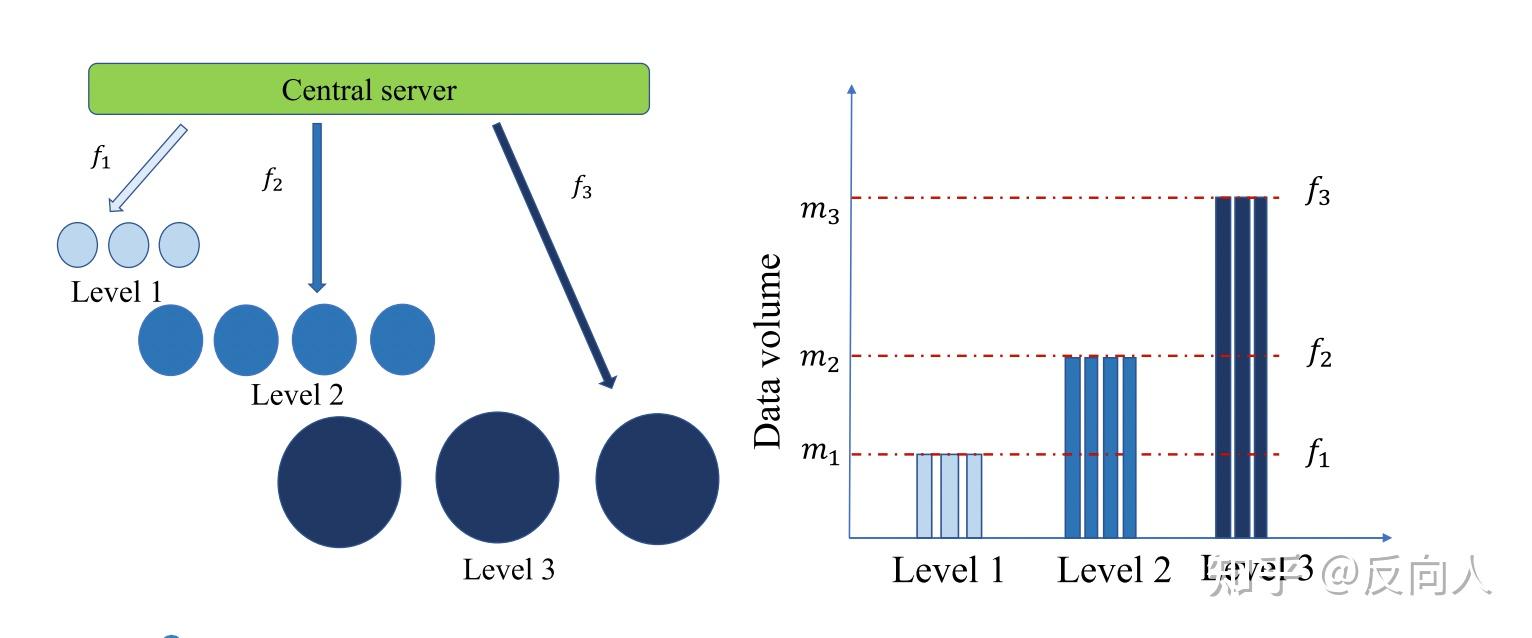
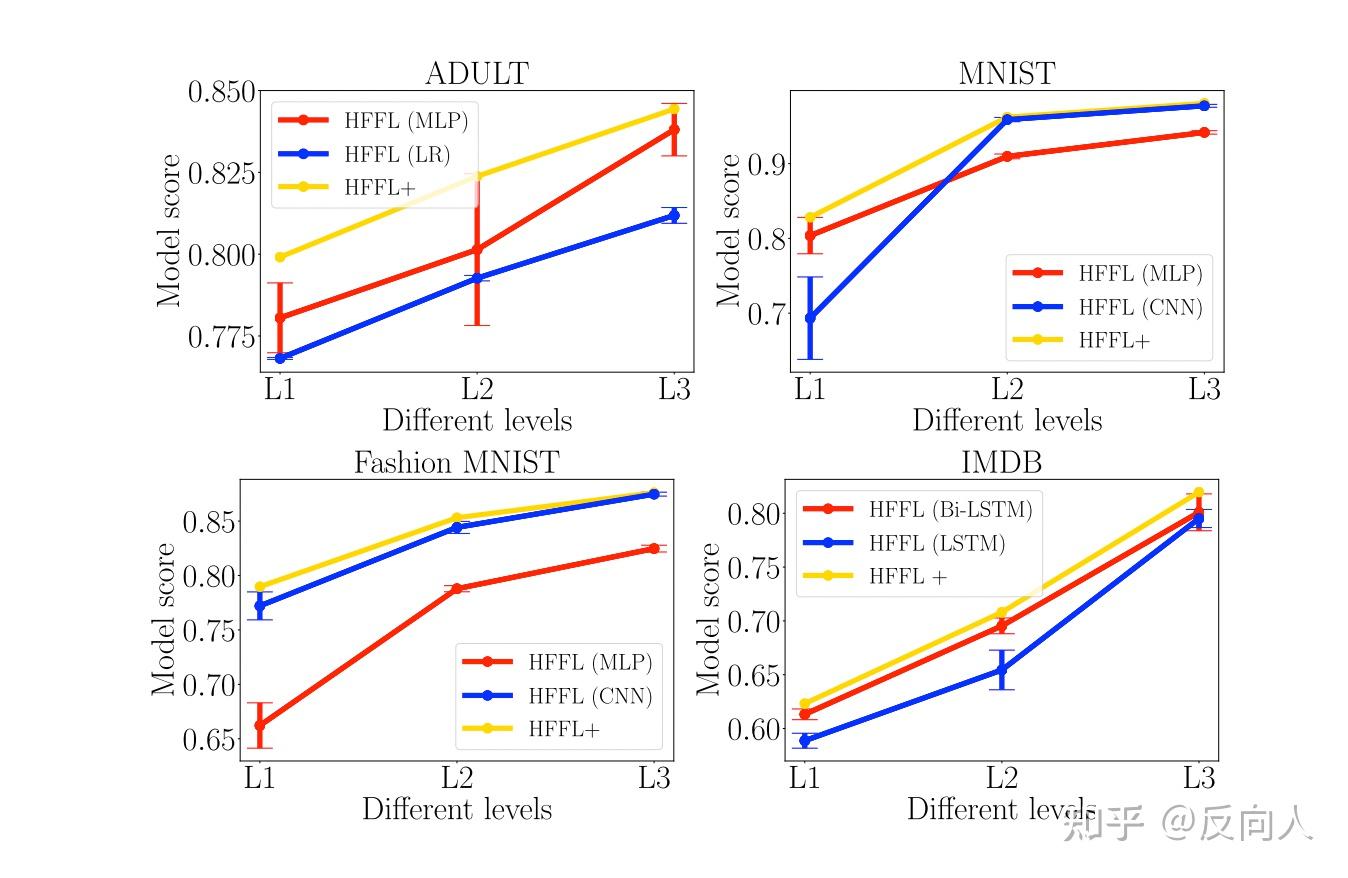
HFFL+ 是HFFL的改进版,通过多次执行HFFL,为每个级别选择性能最好的模型。
作者也是个联邦学习的入门研究生,如果说的不对,希望大佬指正~ 也欢迎联邦学习方向的同学一块交流哈~
使用道具 举报
18
35
2
11
22
0
10
19
8
16
本版积分规则 发表回复 回帖后跳转到最后一页
Archiver|手机版|小黑屋|VV游戏
GMT+8, 2026-3-26 10:36 , Processed in 0.109464 second(s), 23 queries .
Powered by Discuz! X3.4
Copyright © 2001-2021, Tencent Cloud.



 发表于 2023-1-16 03:44:28
发表于 2023-1-16 03:44:28