2
8
11
新手上路
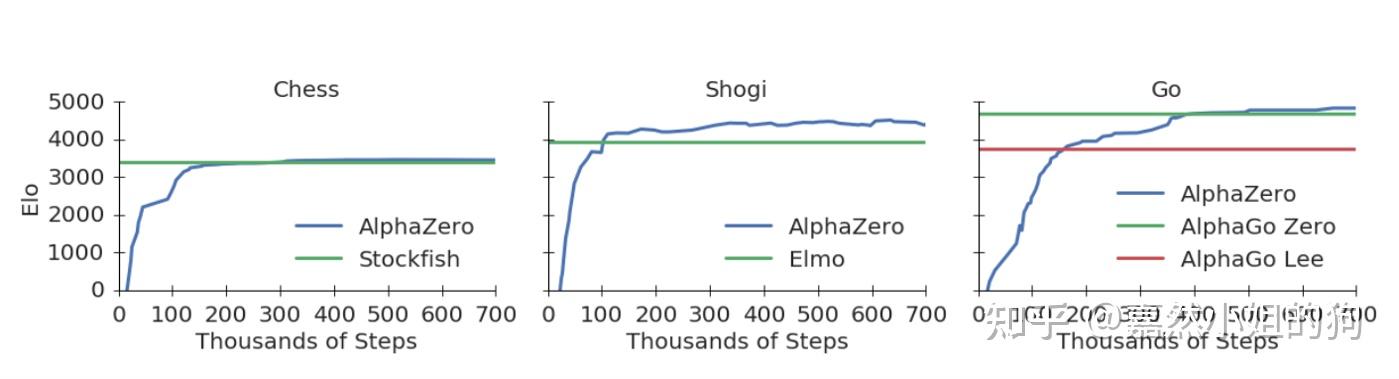
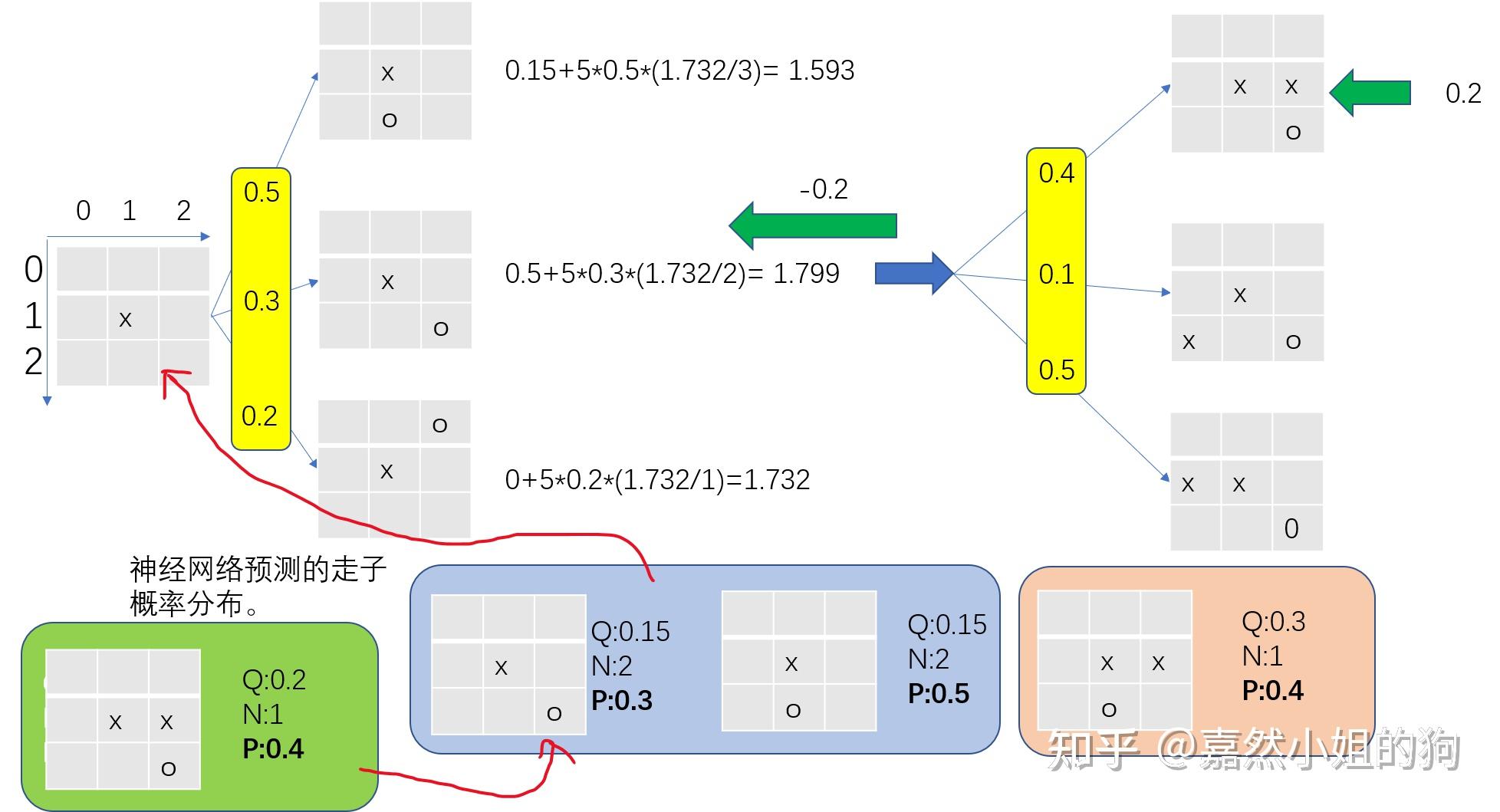
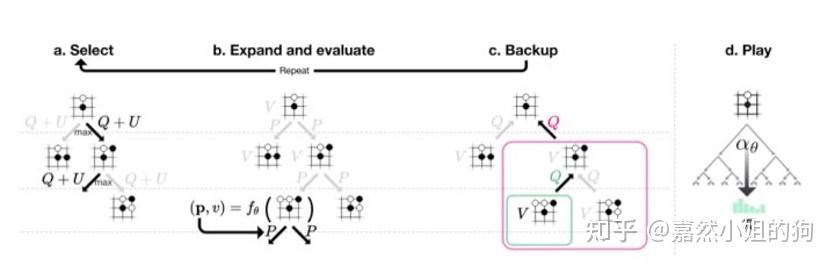
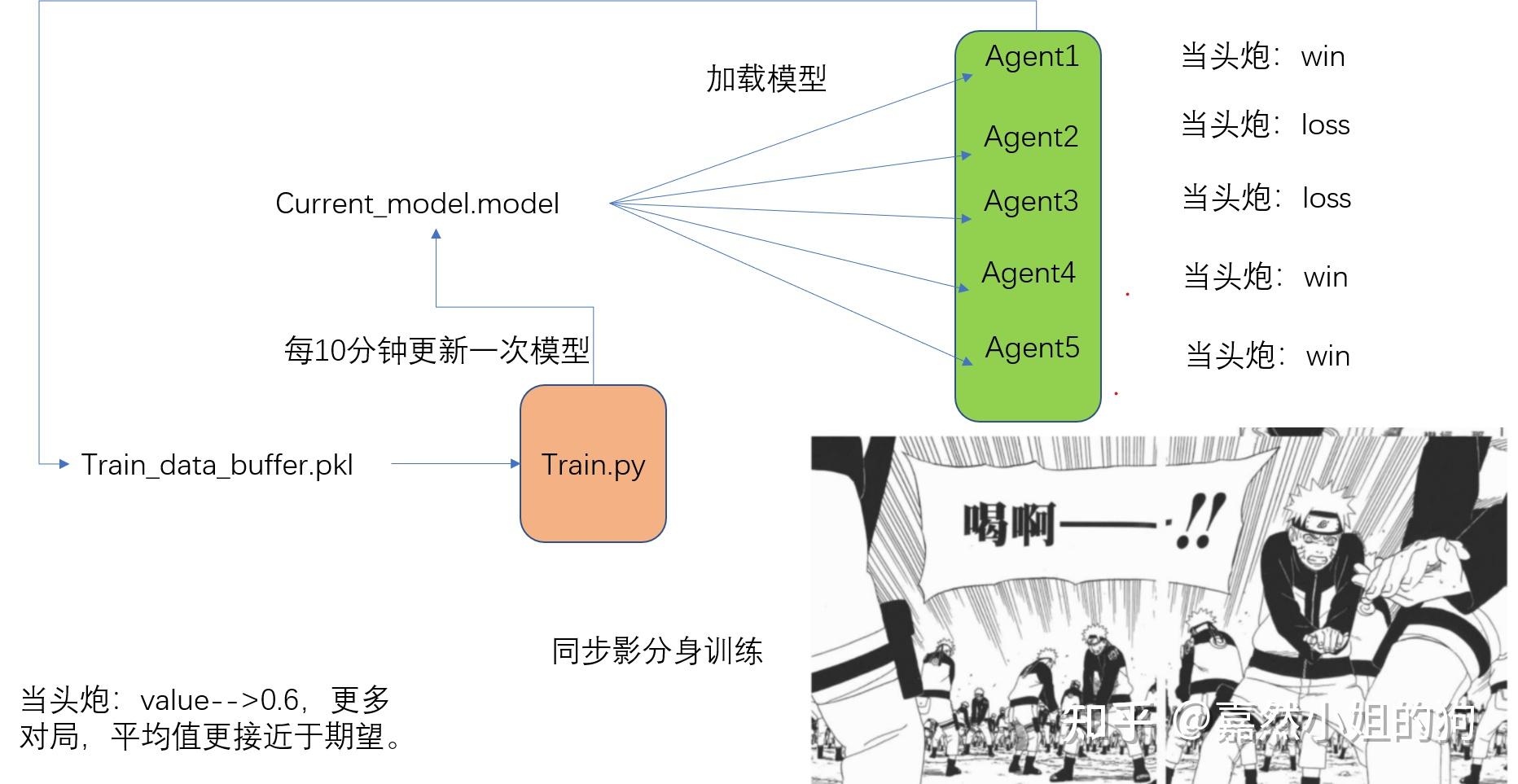
1、AlphaGo用到了人类专家对弈的棋谱进行训练,AlphaZero则完全从零进行自对弈训练。避免了找专家数据的麻烦。 2、AlphaGo用到了人类专家精心设计的特征,AlphaZero则只用到了棋盘的表示特征。让围棋小白也能训练出一个超强AI。 3、AlphaZero棋力更强,是一个通用算法,理论上双人完全信息博弈类游戏皆可籍由此一个算法搞定。 4、省去模型评估的部分,加速训练过程。
使用道具 举报
1
7
14
25
15
10
17
0
3
27
6
32
本版积分规则 发表回复 回帖后跳转到最后一页
Archiver|手机版|小黑屋|VV游戏
GMT+8, 2026-3-26 06:13 , Processed in 0.114214 second(s), 20 queries .
Powered by Discuz! X3.4
Copyright © 2001-2021, Tencent Cloud.



 发表于 2023-3-4 13:33:55
发表于 2023-3-4 13:33:55